
Amazon EC2 names explained
Posted on February 23, 2023 • 10 minutes • 2082 words
Amazon Elastic Compute Cloud (EC2) has over 100 unique instance types with more than 600 size combinations. Picking the right instance type can be a difficult task for even the most seasoned engineer. Running an application on the largest, fastest instance you can afford does not guarantee the best performance.
If you’ve ever wanted to understand instance type names or need help picking the right instance for your application you’ve found the right article. Here’s a moving picture version of this blog post.
And here’s a static picture version of the same information.
A quick disclaimer, I work at Amazon but this is my personal blog reflecting my personal opinion. All of the information was gathered from public sources and from my experience. I wrote this because I wished I had it as a guide when I was first learning EC2.
 Full image
Full image 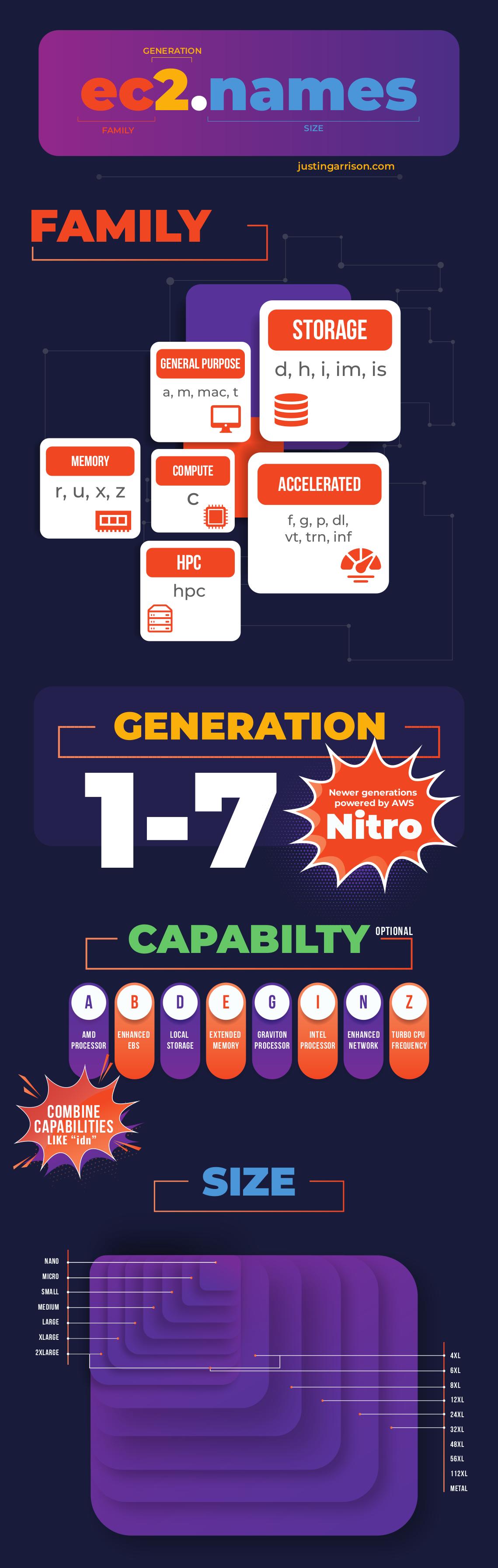{kind=link}
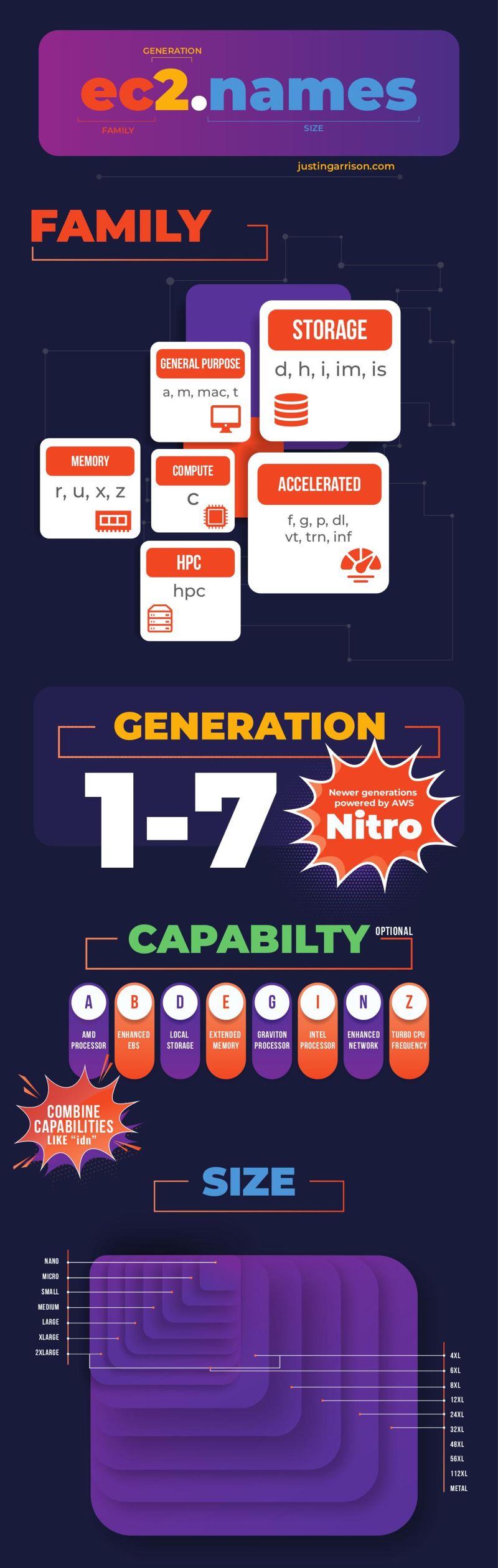
Instance names are made up of four sections.
- Family
- Generation
- Capabilities
- Size
So how do you decipher an instance with the name r7iz.8xlarge?
From the info above we know r is from the memory family which has more memory per vCPU than general purpose.
Specifically it has 8 GiB of memory for every 1 vCPU.
7 means it’s a 7th generation instancy type.
The iz capabilities has a Intel processor (i) running at turbo frequencies (z), and 8xlarge is 8 times bigger than a r7iz.xlarge.

Many capabilities aren’t listed in the name because some families include capabilities by default.
For example, the m family are all EBS and network optimized by default which is usually denoted with the b and n capabilities.
Some of the larger m instances have have local NVMe storage which adds d to the name.
These capabilities aren’t always obvious so you’re going to have to learn about what’s available. The good thing is you don’t need to memorize all of the instance types.
Knowing one instance from the four most common families—general purpose (m), compute (c), memory (r), and storage (d or i)—will get you started with almost any application.
Here’s more info about each of the family groups and types.
Families
Instance families come in six different groups :
- General Purpose
- Compute
- Memory
- Accelerated
- Storage
- HPC
Most categories have multiple type options that refine instance features.
General Purpose
General purpose instances keep a balance between vCPU, memory, and network performance.
Some instances add aditional capabilities to CPU (z) and network (n) and there are multiple CPU options for AMD (a), Intel (i), or graviton (g) chips.
The general purpose group includes: A, M, Mac, T
These are often used as web servers because they have a balance of resources.
The t types can save you money with their burstable vCPU options and are a good choice if your workload CPU usage is similar.
This is the only group with Mac instances which can be used for remote macOS workstations or build farm systems that need Apple tools.
Compute Optimized
Compute optimized only includes the c type instance with different generations, capabilitities, and sizes.
Almost every c instance has a 2:1 ration of memory to vCPU.
If you use a medium instance with 1 vCPU it will have 2 GiB of memory.
If you use a 32xlarge with 128 vCPUs it will have 256 GiB of memory.
These instances are ideal if your workloads need a lot of CPU power and not as much memory.
Memory Optimized
Memory optimized instances are for workloads that consume more memory than CPU.
They have a memory to vCPU ratio ranging from 4:1 up to 32:1.
An instance like r6i.xlarge has 4 vCPUs and 32 GiB of memory while an x2iedn.2xlarge has 256 GiB of memory with 8 vCPUs.
Memory optimized are some of the best instances for clusters like Kubernetes because many workloads are memory bound more than CPU bound. This will let you pack an instance with more workloads than types with lower memory to vCPU ratios.
The memory optimized group includes: R, U, X, Z
Accelerated Computing
Accelerated computing is the most specialized of all of the groups. If you need specialized compute acceleration for your workloads you probably already know.
Most of these instance types have GPU accelerators or specialized machine learning chips.
The only non-machine learning special accelerators are the f1 instances with field programmable gate arrays (FPGAs) and vt1 with Xilinx U30 media accelerator cards.
All of the types have a variety of local storage and high memory.
The GPU types—g and p—have multiple video cards options with varying sizes of GPU memory.
Some instances have multiple accelerators but not all accelerators can be shared with workloads at the same time.
It’s more important to chose the appropriate size for these instances to optimize your usage and keep your costs low.
The accelerated computing group includes: DL, F, G, Inf, P, Trn
Storage Optimized
Storage optimized is exactly what you might think—lots of throughput at low latency. All of these instances will have local storage of various sizes. For most of the instances the memory to vCPU ratio is either 4:1 or 8:1.
All that disk IO wouldn’t be very useful without good network throughput and these instances generally have more network performance at smaller instance size than any other type. They don’t have the fastest network available, but faster than many of the general purpose instance types.
Storage optimized group includes: D, H, I, Im, Is
HPC Optimized
This group only hase one type HPC with 2 options, the hpc6id.32xlarge or hpc6a.48xlarge.
You can get a big instance with Intel (i) or AMD (a) processors with the main benefits being no hyper-threading and lots of network bandwidth.
If you want HPC instances you have a very specific need that needs either 16:1 or 8:1 memory to CPU ratio. They are only available in us-east-2 and GovCloud regions so don’t expect to use these in multi-region deployments.
Generations
Generations are a number 1 through 7 and corelate to how many versions of the instance family has had. Older generations are eventually retired and replaced.
Instance type generations include improvements in processor generations, memory speed, and network performance. Intel based instances usually jump a generation when a new generation of chips are used. I personally can never remember what lake generation is the best with Intel so I use the highest EC2 generation possible.
Graviton also jumps architecture versions with generations. ARM based 1st generation types are using Graviton 1, generations 2-6 are using Graviton 2, and generation 7 is using Graviton 3 (or 3E). Graviton 3 includes support for DDR5 which is another example of general performance improvements in newer generations.
Amazon Nitro is the computer in the computer. Nitro is a series of physical cards that are installed in an EC2 physical server. There are a lot of great re:Invent talks that dive deep into Nitro if you want to learn more.
All modern EC2 instance generations are powered by Nitro. Even previous generations that historically were not powered by Nitro are being converted into Nitro based instances .
It’s usually a good idea to switch to new generations for price and performance benefits, but often times the current generation -1 are the most widely available. There will likely be more regions that have the previous generation and each region will have higher quantities.
Capabilities
Capabilities—sometimes called attributes—identify specific implementations or additional features about the instance. As mentioned earlier, some types have the capabilities by default. In that case the letter isn’t added to every instance but it is assumed because of the instance type itself.
Some of the capabilities are mutually exclusive.
You couldn’t have an instance with ag because those are both processor capabilities and there’s no such thing as an AMD Graviton.
The most complicated capabilities usually include dn or en because those add storage and network performance.
A x2iedn.2xlarge is one of the instances with the most capabilities specifying that it is an Intel processor (i) with a higher memory to vCPU ratio of 32:1 (e), local storage (d), and faster network (n).
The additional capabilities are:
a– AMD processorsg– AWS Graviton processorsi– Intel processorsd– Instance store volumesn– Network optimizationb– Block storage optimizatione– Extra storage or memoryz– High frequency
Size
Instances sizes are almost always twice as big than the previous size. A large is twice as big as a medium and an xlarge is twice as big as a large. The multiples of xlarge are almost always powers of 2 (2, 4, 8, 16), but there are 10xlarge, 12xlarge, and a few other odd xlarge numbers that exist. The main thing with sizes is the vCPU and memory count increase linearly so if you know the ratio of a family or one of the sizes you can figure out the larger sizes too.
Network throughput and storage do not increase linearly and those are often harder to figure out. Many instances have a size where there is a jump in network performance or storage and everything above that size is consistent.
Size is hardest to figure out with shared resources like a Kubernetes cluster. Depending on which workloads are scheduled to which instances will give you a wide variety of performance if you’re not careful. We recommend specifying the instance type or size your workload needs directly in the manifest with a nodeSelector for consistent performance.
Choosing the best instance
The first thing you need to do when picking an instance type is understanding your workload’s needs. You need to find the bottlenecks and limits of your application before you decide on an instance to use.
Benchmarking on your laptop is not the right approach. Unless you`re doing remote development in EC2, your local development environment is very different than where the application will run in production.
Running a single Apache bench or hey benchmark might get you started, but you need to have a way to continuously profile your application in production. Knowing how your application performs with production data, users, and environment is the only way to know for sure. Invest time in collecting data from production before optimizing your instances.
Once you know your application’s bottlenecks you can identify the correct ratio of performance between CPU, memory, network, and storage. Keep in mind that running applications on shared instances—as is common with Kubernetes—your application will perform differently. The way Linux shares a CPU is very different from high level reservations and you should request instance types in your workload manifest.
EC2 instance selector
I’m a big fan of the EC2 instance selector
CLI and go library.
It can be used to find any instance that matches your performance needs.
Memory, vcpus, network performance, EBS throughput are some of the options to find available instances based on your region.
The --service option is one of my favorites because it automatically removes instances that are not compatible (e.g. --service eks).
EC2Instances.info
For a bit more visual appreach to finding instances you can use EC2Instances.info . It is a GitHub repo hosted by Vantage and makes it a bit easier to search through. One of my favorite options is the full CSV export which I regularly download to be able to query and sort offline.
Conclusion
The most important thing to know when picking the “best” instance is it depends. The reason there are so many different instance types is to allow for a variety of applications to run at optimal performance and cost.
If you are running production workloads and want consistent performance the best investment you can make is to continuously profile your application’s performance. This will not only give you a baseline for scaling, but it will help you find regressions and bottlenecks.
If you understand your application’s requirements, choosing an instance to match can be a lot simpler. This can be difficult in an environment where the infrastructure is selected by a platform team and not the application developers. Using a nodeSelector in Kubernetes can make sure your workload is scheduled to the appropriate instances even in a shared environment.
Glossary
- GiB = gibibyte is measured in powers of 2 while GB is powers of 10. 1 GiB is 230 and 1 GB is 109
- IO = Input/output. This is the action of reading and writing to a storage device.
- vCPU = A virtual processor representing a single processing thread from a physical CPU.
The infographic was created by Adeeba N. on Upwork .