
No SDN Kubernetes
Posted on September 26, 2016 • 5 minutes • 983 words
Kubernetes networking has a few requirements . They are:
- Pods are routable on a flat network
- Pods should see their own routable IP address
- Nodes can communicate with all containers
How these requirements are implemented is up to the operator. In many cases this means using a software defined network “SDN” also called an overlay network (e.g. flannel , weave , calico ) or underlay network (MACvlan, IPvlan). The SDNs all accomplish the same three goals but usually with different implementation and often unique features.
But the networking requirements doesn’t mean you have to run an SDN. It also means you can implement a traditional SDN product in a non-traditional way. Let’s look at the simplest solution for networking in Kubernetes.
Route tables
For this example we have two Kubernetes nodes. The nodes are joined together on the network and each has Docker running using a specified NAT address (using -bip option).
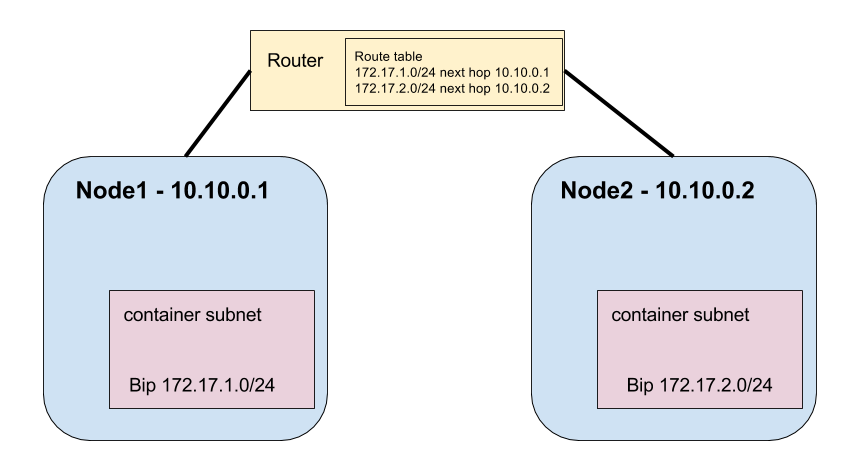
Node1 is running containers on subnet 172.17.1.0/24 and node2 is running containers on the subnet 172.17.2.0/24. So how can we tell containers on node1 how they can route to node2? The same way we can tell any two subnets to route to each other, we update the router’s routing table with a next hop for the subnet.
In this case we can tell our router that all routes going to 172.17.1.0/24 need to go to node1’s IP address 10.10.0.1 (the next hop) and all routes going to 172.17.2.0/24 need to go to 10.10.0.2. This concept works if you’re in a cloud provider (assuming your provider allows you to define routes for your private network) or on-prem. Every network has routing tables.
Examples for adding these routes in GCE or AWS can be seen in
.
That’s literally all you need to do. If your host’s IP address change you can update the route table. If you add a new node you just add the route.
But what’s the downside to doing this?
- You can’t reuse 172.17.1.0/24 anywhere else in your network unless your network routes are segmented (as with a VPC on a cloud provider).
- You need to manually assign the container subnet on each node and update the route table which can be tedious.
- If nodes are on separate subnets you may need to setup routes on multiple routers.
- It may involve a team/resource outside of your control or expertise.
Host routes
Likewise, you can do the same route options locally on each node in the Kubernetes cluster. Let’s look at our two example nodes again.
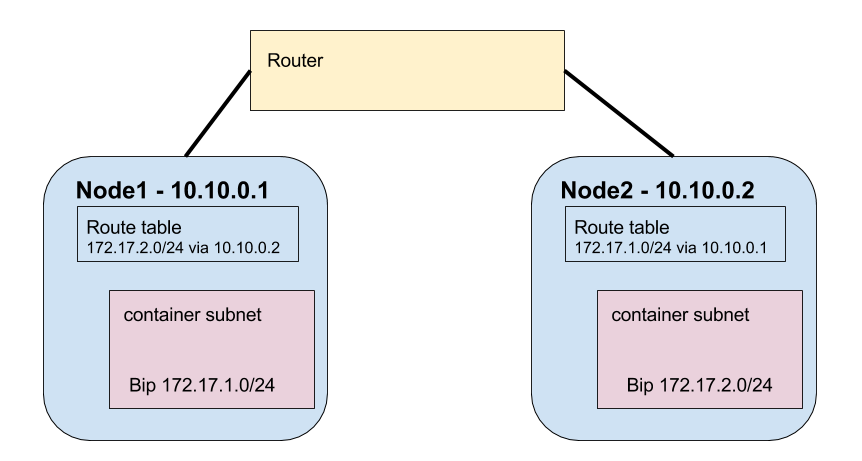
In this case, our route table is applied directly on the nodes. This can be done by running
ip route add $DOCKER_SUBNET via $NODE_IP
You’ll need to run this command for any nodes in your Kubernetes cluster on each node. While that may sound like a lot, it can be easily scripted. I would suggest making a simple hash table and then looping through it with a script. You can automate applying the script via cloud-init or a script run by systemd or cron.
This method doesn’t have the same downsides of managing your routes on the router. In this case, many of the previous limitations don’t apply. The only limitations are
- Nodes need to be connected via layer 2 (single hop)
- You need to keep track of container subnets and node IP addresses
Unlike the previous situation, host routes don’t rely on an external team (assuming you manage the nodes) and you can re-use a container subnet in different clusters because routes to the subnets are only visible to the hosts in that cluster.
As an added bonus, you can allow any machine to access pods without a proxy by simply adding the routes for the container subnets. Once the subnets are added that host can route to pod IPs just like any other container. The service IP subnet will need to be pointed to a node running kube-proxy because those rules are managed by incoming iptables rules rather than host routes. Pods will appear as any other host on the network.
For a better visual representation you can also check out
thockin ’s slides

Other options
While I find it conceptually easier to manually define routes, I understand there are situations that would benefit from having an SDN
- You don’t have access to route tables (on the router or on the host)
- Your hosts fluctuate (dynamic scaling group?) and route management is cumbersome
If you must run an SDN I would suggest you look into flannel’s backends . The default is to use a UDP tunnel, but it is also capable of setting up host routes or automatically managing AWS or GCE routes .
Calico sets similar route table rules on the host with some added iptables policies for making sure workloads and traffic is securely routed only to the desired destination. That may or may not be desired.
In either case, I recommend not adding new or unnecessary complexity to your infrastructure. This holds especially true when trying to introduce new ways of thinking about how you manage your applications. If your current infrastructure doesn’t have dynamic scaling, automatic subnet routing, and network isolation don’t try to implement those things while also introducing Kubernetes to your environment. Start small, replace what you need, and understand the components as you go.
Conclusion
Kubernetes network requirements help solve real world problems with distributed applications. The important thing to know is
There’s 👏 no 👏 such 👏 thing 👏 as 👏 container 👏 networking
It’s just networking. Anyone who tells you differently is either trying to sell you something or doesn’t understand how networking works. Yes, you can use an SDN to make the packet routing automatic (i.e. harder to troubleshoot), but you don’t have to.
If you have questions you really should join the Kubernetes slack channel or send me a DM on twitter .