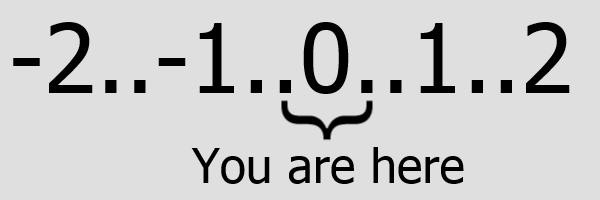
Version Number 0: A New Way to Do Software Versions
Posted on August 8, 2013 • 4 minutes • 698 words
I had this idea while driving into work with a friend and, like a lot of my ideas, I just wanted to throw it out there to discuss how, why, and what’s wrong with the idea. Please feel free to leave a comment to discuss.
Disclaimer, I’m not a software developer so I really have no say into how this actually works.
How Version Numbers Should Work
Version numbers are a unique name or number assigned to a specific version of the software. There can be public and internal versions but they typically increment from 0 -> ∞ or a — z. Often times there are also “code names” for releases which sometimes become more popular than the actual names themselves (see Ubuntu releases ).Incrementing version numbers usually are the form major.minor.fixes (e.g. 1.3.0 is major release 1, minor release 3, with 0 bugfixes). Incrementing versions can also have letters to help designate (pre)release state (e.g. 2.0.0b2 is the second beta release for version 2.0). Some systems also use odd numbers for development and even numbers for production (see the Linux kernel ).
How Version Numbers Actually Work
In many cases the above systems work. But lately I am not sure version numbers make sense, nor are they used in a way that helps customers. Software versions in a lot of situations are either a reference to the year the software was released (or supposed to be released) or are just a pissing contest to make sure the number is bigger than the competition (see Firefox . Version .01 -> 3.6 in 10 years; version 3.6 -> 23.0 in 17 months).
Oh and don’t forget the global assumption that anything <1 is complete crap so you had better change your version number from 0.25 to 2.6 (thanks Puppet ).
How Version Numbers Could Work
So what if there was another way. What if, for the sake of the end user, current software was always just version 0 (naught). It doesn’t matter how many iterations or releases you’re on, the release you are shipping is 0. In other words, the current version of Firefox would always just be called Firefox.
If this were the case, your support model will be to support versions -2 through 0. As new releases come out the older versions are known as negative releases or, depending on your release cycle, yearly releases. The version that is one major release old (and came out six months ago as of writing this) would be Firefox -1 (2013.02). People can easily look at this number an know when their software came out and also how current they are with the shipping version. Bugfix and minor releases would be handled in a similar manner by decrementing the version number of out of date software rather than incrementing newer software. Once you are up to date you are back to 0.
Likewise, beta versions would be 1 and alpha would be 2. I’m not sure there would be many public versions above 1 and 2 but maybe development would be 3–4 and not ever released to the public.
When I thought about it more, this is the way websites work. Not because it was designed this way, but because customers don’t have a choice in using an old version. They are always on the version that is available. Similarly, other things in the physical world (such as cars) often work this way. They sometimes append the year for identification purposes, and because they release most cars yearly, but a Corolla is always a Corolla. It is only made old by the fact that a new version has come out. Luckily for the customer, they don’t have to know what mark (a.k.a. version) the car is on, they just have to know they want the current one (FYI the Corolla is currently on MKXI or version E160).
I know this idea doesn’t work well with version control, tags, blah, blah, blah. But it seems like something that works in the physical world, is highly consumer friendly, and because it gets version numbers out of the way, could be a very good thing.
Originally published at 1n73r.net on August 8, 2013.